-

-

-

-

-
URLをコピーしました
入社半年のIT未経験者が挑む!生成AIプロジェクトに飛び込んでみた
-
-
-
-
-
URLをコピーしました


はじめに
こんにちは、今年4月に入社したばかりのカマGと申します。
私は文系の大学を卒業したため、ITに関しては未経験であり、ほとんど知識がありませんでした。入社後は、6月末までJavaとSpringフレームワークを中心とした研修を受けました。そして、7月初旬に配属先が決まり、配属初日に生成AIプロジェクトに参加することを知りました。
配属当初は、生成AIについての知識がほとんどなく、最新の技術に触れることへの期待感があった反面、新参者の自分に務まるのかという不安な気持ちもありました。配属するまでは、生成AIについてのニュースをたまに耳にしたり、ChatGPTを要約などで利用したりする程度でした。
そのため、生成AIの処理の流れや、それがどのような技術で成り立っているかなどの知識は全くありませんでした。そんな自分が、生成AIプロジェクトに飛び込んでみての取り組みをご紹介します。
社内での生成AIプロジェクトの概要
現在、私が参加しているプロジェクトは、社内の生成AI研究の一環として取り組んでいるものです。
具体的には、LLM(Large Language Model)を利用してユーザーが入力した質問に答える社内チャットボットの開発を行っています。 このチャットボットでは、RAG(Retrieval-Augmented Generation)を利用しているため、一般的な質問だけでなく、社内情報に関する問い合わせにも対応しています。
LLM(Large Language Model)とは
Large Language Model(LLM)は、現代の自然言語処理技術において非常に重要な役割を果たしています。
これらのモデルは、大量のテキストデータと深層学習技術を組み合わせることで構築され、人間のような自然な文章を生成する能力を持っています。AIが「バナナの色は」に対して、「黄色です」「緑です」「茶色です」などの続くパターンの確率を学習し、予測した上で文章を生成しています。

代表的なLLMには、Meta社のLLaMa3.2やGoogle社のPaLM2、そしてAnthropic社のClaude3などがあります。私のプロジェクトでは、ChatGPTで使用されているものと同じモデルであるOpenAI社のGPT-4oを利用しており、その卓越した性能に日々新しい発見をしています。これらのLLMの背後には、人工ニューラルネットワークという技術が用いられています。
人工ニューラルネットワークは、人間の脳の機能を模したコンピュータシステムで、テキストデータの文脈やニュアンスを理解し処理することを可能にしました。これは、私たちが家族や友人、職場の先輩と何度も会うことで顔と名前が一致する脳の仕組みに近いと思いました。この技術の1種であるTransformerをベースとしたChatGPTの誕生により、LLMは急速に普及しました。
最近では、このような人工ニューラルネットワークを用いた機械学習の成果が、ノーベル物理学賞を受賞するほどの注目を集めています。私は、最初に「LLM(大規模言語モデル)」という言葉を聞いたときは、正直、難しそうだなと感じました。
しかし、普段何気なく使っていたChatGPTの裏側にこんな仕組みがあることを知り、とても驚きました。特に、脳の機能を模しているという点が印象的で、一見関係のなさそうな生物学的な要素から新たな発想を広げているのがすごいと思いました。
また、膨大な言葉のパターンを学習して自然な文章を生成する仕組みは、私たちが言葉を覚え、会話ができるようになる過程に似ている部分があると感じました。
RAG(Retrieval-Augmented GenerationまたはRetrieval-Augmented Generative)とは
RAGとは、生成AIが情報を生成する際に、データベースなどから情報源を検索して、生成に情報を補完する技術のことです。
私は、RAGについて、持ち込み可のテストで、書籍やノートを持ちこんで解答するようなイメージで理解できました。RAGを利用することで、生成AIが学習した既存のデータに加え、外部の情報源を参照することで、より正確で信頼性の高い情報を提供することが可能になります。
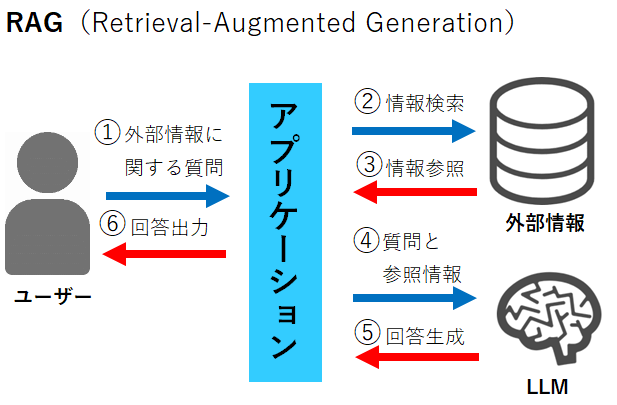
しかし、書籍やノートから特定の答えを探すのに時間がかかるように、RAGを利用すると生成AIの回答に時間がかかってしまうことがデメリットです。RAGとともに話題に出るもので、ファインチューニングというものがあります。
ファインチューニングとは、既存の大規模言語モデル(LLM)に追加の情報を学習させ、特定のニーズに応じた回答を可能にする手法です。
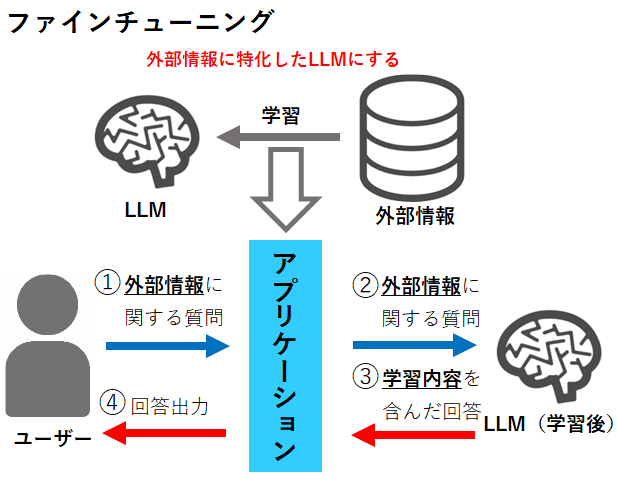
先程の例を用いると、RAGが持ち込み可のテストであるのに対して、ファインチューニングは自分で勉強して覚えた後にテストを受けるようなものです。これにより、独特な表現や概念にも対応しつつ、既存のLLMの能力を生かすことができます。
しかし、テスト勉強に時間や労力がかかることと同様に、ファインチューニングでは、追加学習用のデータ作成にコストがかかることや、LLMのモデルが変わるごとに追加学習を行う必要があるなどのデメリットもあります。それに比べると、RAGは情報を探すだけで、学習データの準備やモデルごとの学習は不要であるため、コストを抑えられます。
私のプロジェクトでは、社内情報を守りつつ、情報の正確性が必要なことに加え、運用コストを抑えるためにRAGを利用する形になりました。RAGについて知るまでは、外部情報を用いて必要な情報をChatGPTの生成に活用できるとは思いもよりませんでした。以前の私と同じように、RAGについて知らない人はまだ多いのではないかと思います。
個人的には、今後RAGが広まり、個人で生成内容のカスタマイズが可能なChatGPTのようなサービスが広がっていくと、面白くなると感じました。
おわりに
今回は、生成AIプロジェクトの概要とLLM、RAGについて新人なりに紹介しました。生成AIプロジェクトへの参加を通じて、今後も学びを深めながら成長を続けていきます。
次回は、プロジェクトでの開発の取り組みについてより具体的にお話しします。この記事が少しでも参考になれば幸いです。